布隆过滤器(BloomFilter)
常见问题
- 编辑器软件需要检查一个英语单词是否拼写正确
- 广告、新闻推荐时判断一篇文章是否已经推荐过
- 邮箱垃圾邮件过滤
常规思路
- 数组
- 链表
- 树、平衡二叉树、Trie
- Map (红黑树)
- 哈希表
对于简单的少量数据处理,上述数据结构基本能够满足要求。但随着互联网不断的发展,带给我们最大的挑战就是当数据量呈现爆发增长时,如何在效率、存储上获取最优的解决方案。设想如果需要处理、匹配的数据量达到百万、千万时,不论是常规的Map还是性能优异的Hash表,都将面对检索性能极速下降、存储量持续上升的问题。这时候我们就需要用到布隆过滤器(BloomFilter)。
背景
布隆过滤器由巴顿.布隆于一九七零年提出,可以用来判断一个元素是否出现在给定集合中的重要工具,具有快速,比哈希表更节省空间等优点,而缺点在于有一定的误识别率(false-positive,假阳性),它可能会把不是集合内的元素判定为存在于集合内,不过这样的概率相当小,在大部分的生产环境中是可以接受的。
基本特性
- 一个很长的二进制向量(通常直接采用位数组)
- 一系列随机函数 (哈希)
- 综合空间效率和查询效率高
- 有一定的误判率(也可以说是通过引入误判率这一维度,以便在效率和空间上获得最优)
原理
如下图所示,S集合中有n个元素,利用k个哈希函数,将S中的每个元素映射到一个长度为m的位(bit)数组B中不同的位置上,这些位置上的二进制数均置为1,如果待检测的元素经过这k个哈希函数的映射后,发现其k个位置上的二进制数不全是1,那么这个元素一定不在集合S中,反之,该元素可能是S中的某一个元素(参考1);
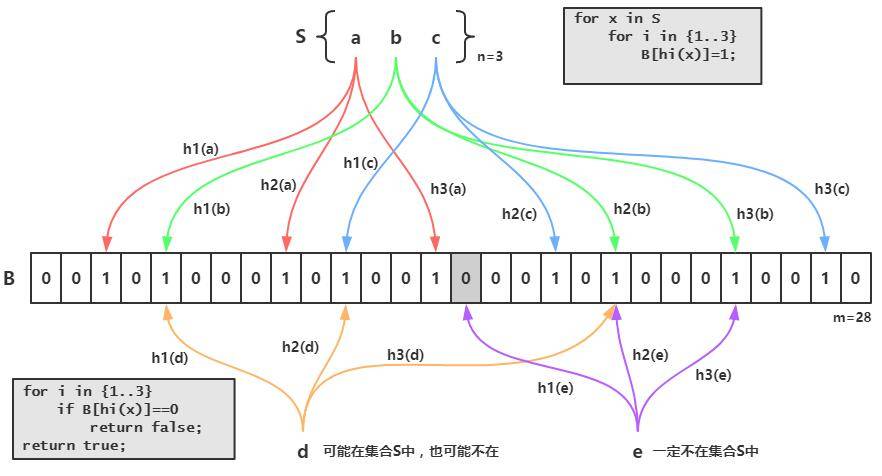
最优判率
由上面的算法介绍,和布隆过滤器判率相关的点有如下两个:
- 容器数组长度(m);
- 哈希函数个数(k);
容器数组越长,可以存储的差异数据越多,但占用的存储空间也就越多。当使用的哈希函数个数越多,生成的结果越能精确区分原始数据,但随之而来的问题则是容器数组填充的速度也会变快。
为了估算出k和m的值,在构造一个布隆过滤器时,需要传入两个参数,即可以接受的误判率fpp和元素总个数n(不一定完全精确)。至于参数估计的方法,有兴趣的同学可以参考维基英文页面,下面直接给出公式: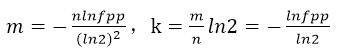
- 哈希函数的要求尽量满足平均分布,这样既降低误判发生的概率,又可以充分利用bit数组的空间;
- 根据论文《Less Hashing, Same Performance: Building a Better Bloom Filter》提出的一个技巧,可以用2个哈希函数来模拟k个哈希函数,即gi(x) = h1(x) + ih2(x) ,其中0<=i<=k-1;
- 在吴军博士的《数学之美》一书中展示了不同情况下的误判率,例如,假定一个元素用16位比特,8个哈希函数,那么假阳性的概率是万分之五,这已经相当小了。
支持的操作
常规的布隆过滤器只支持如下两种操作:
- 判断指定数据可能存在于集合中
- 往集合中添加数据
删除数据?
上面说了,一般常规的布隆过滤器只能添加数据,不能删除数据。为了支持删除操作,常见的一种做法是通过将位数组扩展位值数组,比如采用int数组代替bit位方式实现对每一「格」数据的计算,删除时至少减少计数即可。
但这同样会有另外一个问题,hash本身就存在冲撞的情况,因此删除的时候如何确定:你当前删除的数据就是前面添加的数据?比如往布隆过滤器添加了数据A,存在数据B在某个哈希映射下结果和A是相同的或B的哈希结果是A的子集,那么使用B其实是可以删除(或部分删除)A存储的结果的。
扩容
常见布隆过滤器实现
- 本文链接:https://blog.springfavor.cn/2019/01/26/布隆过滤器-BloomFilter/
- 版权声明:The author owns the copyright, please indicate the source reproduced.